
Case Study: A model for biomechanical simulation data
The @neurIST project (see introduction) dealt with biomechanical analysis of a large number of individual brain aneurysms, in order to improve the estimation of their risk of (often deadly) rupture. The simulations of the biomechanical problems generated a large amount of input and output data. In order to organise the different data items, their structural properties were formalised in a logical data model. The resulting data base schema permits management of the simulation data in a way maximising its usefulness for statistical analysis and enabling future reuse, including practical multi-case experiments.
This case study describes my contribution within the context of the project's relevant results. My work for @neurIST took part mostly during my time at NEC and was finished at CMM as subcontract work for the project.
Kinds of simulation data and their relationships
The @neurIST biomechanical toolchain produces a lot of data: intermediate and final, structured and unstructured, huge and tiny, costly and cheap to produce. It also uses clinical data like medical images, and potentially other measured physiological data like blood pressure or haematocrit. The most important data classes are medical images, aneurysms (the anatomical structure of interest here), geometric representations of aneurysms (which are only implicitly represented by the medical images), computational analyses (see also below), and potential risk factors, i.e. biomechanical characterisations of aneurysms.
The relationship of these data entities can be non-hierarchical, in particular if we want to manage variants: We can have several aneurysms per patient, and several imaging series at different points in time, not all of which necessarily show all aneurysms. From images we derive geometric representations of the regions of interest in the vasculature, which again might cover only a subset of the aneurysms. Building on geometric models, we create representations of computational analyses, such as blood flow analyses. This requires an appropriate clipping of the geometry, geometric characterisation of the aneurysm interior (by defining a neck), definition of boundary conditions and so on.
Data modelling
The crucial task in data modelling is to find the right entities: not too coarse and not to detailed. The guiding questions here are
- What aspects could be changed or used independently?
- Can there be possibly a one-to-many or even many-to-many relationship between candidate entities?
A good example is the representation of the different subsets of the aneurysm geometry needed for the different types of analysis (a tight neighbourhood of the aneurysm for shape analysis, and a larger portion for blood flow). Instead of making those trimmed geometries first class data entities, we preferred to explicitly represent the complete processed geometry encompassing the whole region of interest, plus the trimming specifications, from which the trimmed geometries can be derived automatically.
Another, more interesting, example is the definition of a biomechanical simulation. It is beneficial to separate the definition of the computational problem (analysis) from its execution (run). For a single problem definition, there could possibly be many executions (runs), even using different algorithms or applications, as long as they yield (ideally) the "same" results. Therefore, the project captured the essence of the biomechanical problem in an analysis entity, consisting at its core of an abstract problem description (APD). This description is "abstract" in the sense that it is independent of any concrete simulation application which could be used to compute a solution of the biomechanical problem. Nevertheless, it is complete, so that input for any type of simulation package can be generated automatically, see the description of the tool chain automation.
A very important entity for grouping analyses is experiment, a concept which might escape attention initially. Running variants of analyses is very useful for instance to compare the effects of using different modelling choices, boundary conditions, or material parameters. These variants however must be kept apart for purposes of subsequent statistical analysis; we assign them to different experiments to group them.
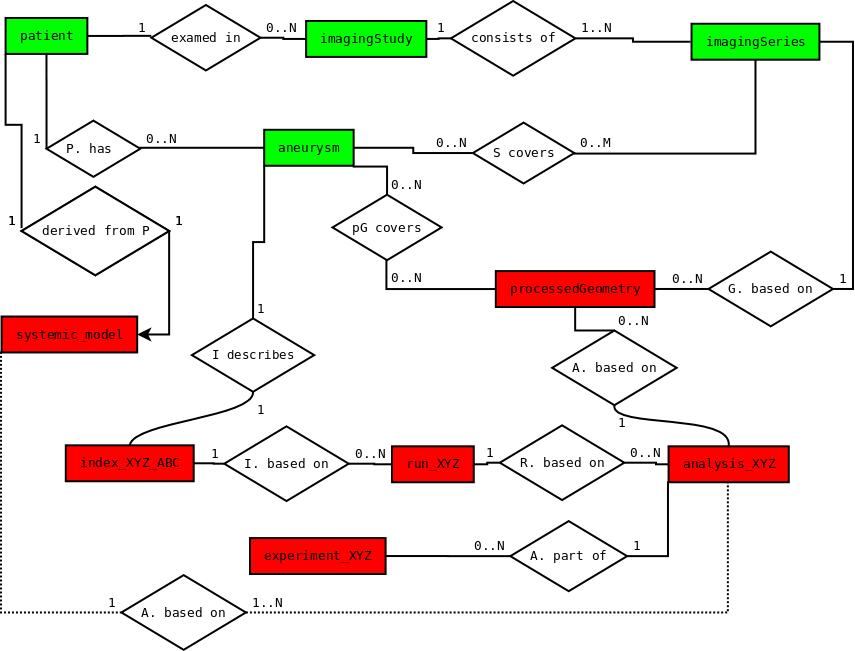
The relationships of the most important pieces are visualised in an entity relationship diagram. Filling in the details resulted in a SQL-based data definition of considerable size. This SQL schema was used to manage the results of processing hundreds of cases using a DBMS (in this case, MySQL). This data base links the biomechanical simulation data to the underlying clinical data on the one hand, and to statistics-based knowledge discovery tools on the other hand.
Looking ahead
The concrete details of this work are clearly specific to the problem of biomechanical simulation of aneurysms. The concepts however easily generalise to other large-scale simulation based systems. The crux of the matter is to find the right data abstractions, permitting easy manipulation and transformation of data e.g. for defining variants of simulations. In this case, we defined an abstract yet complete description of the computational problems supporting essentially this kind of manipulation. Thus, one gets a very powerful system at one's fingertips which can be regarded as a kind of "virtual data base" of analysis results: existing, deleted, or yet-to-be-computed ones.
For instance, one could ask whether certain drugs have an influence on aneurysm rupture risk by selecting a relevant population of cases in the data base, transform all abstract problem descriptions according to the resulting change in blood viscosity, run them, and compare the extracted risk indicators. This is a typical example of what the project called "multi-case analysis": By leveraging the previous geometry processing and problem definition work, variants of these problems can be generated and run automatically, with no more manual work needed than for a single case.
My role in developing a data model for biomechanical simulations
I developed the conceptual schema for all data related to the @neurIST biomechanical tool chain. I specified the essential processes and data entities in this tool chain, linking each process to a precise definition of its inputs and outputs. In collaboration with Christian Ebeling (FhG SCAI), I formalised this conceptual model into a complete, detailed description of the logical data model using SQL as a data definition language. The schema contains about 80 tables, and is self-documenting using meta-tables describing tables and attributes. It supports easy references to relevant clinical data (images, aneurysm information) managed using a different schema. This work involved intense collaboration and communication with the project partners responsible for- the various details of the tool chain
- the management of the clinical data, including the legal restrictions
- the statistical use of these data for finding risk factors
My developments were oriented towards the goal of supporting the multi-case processing scenario of the tool chain: For large set of cases, their existing abstract problem descriptions can be automatically transformed into variants (e.g. by replacing boundary conditions), which can then be executed and inserted into the data base. This ability is a very powerful tool in the hands of a researcher or engineer who wants to run new computational experiments. The manual work needed to actually carry out the experiment can be reduced significantly to be independent of the number of cases processed.
Many scientific explorations become only practical when having access to such a system.